The moment I understood the gap was not about tools came from a single project.
I built a research agent. It monitored sources I had chosen. Every morning, it delivered me a structured digest — key insights, data points, what mattered, what to ignore.
I showed it to a colleague who uses Claude every day.
She had no idea this was possible.
She used the same model. The same subscription. The same access.
The difference was not the tool. It was how I had learned to think about what the tool could do.
That gap is real. And it is larger than most people want to admit.
88% of organizations now use AI in at least one business function.
Only 6% qualify as high performers — companies getting measurable impact on their bottom line from AI.
The other 82% are using AI. They are not getting results from it.
I spent months studying what separates the two groups.
It is not the model. It is not the subscription tier. It is not which company built the AI they use.
Here is what it is.
What the 88% Actually Do
The 88% are not bad at AI.
They are using it the wrong way — and most of them do not know it.
I see the same patterns everywhere.
They prompt reactively. A question comes up. They open Claude or ChatGPT. They type the question. They read the answer. They close the tab. No context. No follow-up. No system.
They treat AI as a search engine replacement. The interface is different. The behavior is the same. They seek, they retrieve, they move on.
They judge AI by individual outputs. One bad response and the tool is “not good enough.” One good response and they think they have figured it out. Neither tells them anything about the system they are using or how to improve it.
They never build context. Every session starts from zero. The model knows nothing about them — their work, their voice, their goals, their constraints. They re-explain themselves every time. The sessions never compound. Each one is isolated.
They add tools when results disappoint. Output not good enough? Subscribe to another tool. Stack grows. Results stay flat. The problem was never the tool.
They measure AI use by time spent. “I use AI all day” is not a measure of impact. It is a measure of activity. The two are not the same.
The 88% treat AI like a vending machine.
Put in a request. Get out an output. Move on.
The 6% treat AI like a team member they have been onboarding for months.
What the 6% Do Differently
Four behaviors separate the high performers. None require a different model or a more expensive subscription.
They build persistent context.
The 6% do not re-explain themselves every session.
They have a context file. A system prompt. A document loaded before every conversation. The model already knows who they are, what they are building, and what tone they use.
When I built my research agent, the first thing I wrote was not a prompt. It was a context document. Who I am. What I cover at EchoNerve. What format I need digests in. What counts as signal versus noise for my work.
That document made every session after it more useful than every session before it.
The output quality did not improve because the model got better. It improved because the model finally knew what I needed.

They use agents, not prompts. A single prompt gets a single answer. The 6% design workflows where one agent researches, one drafts, one edits. Each has a defined role. Each produces a structured output the next one uses. They stop being the connector between AI tasks. When you copy an output from one prompt and paste it into the next, you have not automated anything. You have outsourced typing. You are still the connector. The coordination overhead still lives with you. An agent-based system removes you from between the steps. You design the system once. You review the output at the end. Everything in between runs without you.
They test and document what works. They keep a prompt library. They write down which system prompts produce better outputs. They run the same task with two different instruction sets and compare the results. They iterate like engineers, not end users. Most AI users have no record of what worked and what did not. They run the same types of prompts in slightly different ways every session. They never improve systematically because they never document what they tried. The 6% treat prompt development as a skill. They track it, refine it, and build on it.
They know when not to use AI. This is the one most people miss. The 6% are precise about where AI adds value. They do not automate judgment. They automate the parts that do not require judgment — so they have more time for the parts that do. They ask one question before every task: does this step require a decision only I can make — or does it require a decision at all? If yes, they do it themselves. If no, they build a system for it. The 88% automate the wrong things. The 6% automate the right ones.
The Three Gaps
The difference between 88% and 6% comes down to three gaps. Most people have all three.
Gap 1: The Context Gap Most people give AI a task. The 6% give AI a role, a context, a constraint, and a format. “Write a summary of this article” is a task. “You are a research analyst for EchoNerve. Extract the five most relevant data points from this article. Format them as numbered lines. No opinions. Flag anything that contradicts previous research I have shared with you.” That is a context-driven instruction. The output difference is not incremental. The 88% give AI a task and edit heavily. The 6% give AI a role and use the output with minor changes. The time difference per piece compounds across a week, a month, a year. Context is not a trick. It is the baseline the 6% work from and the 88% skip entirely.
Gap 2: The Systems Gap One task equals one result. One system equals compounding results. The 88% are always starting from scratch. Every piece of work requires the same cognitive overhead as the first time they did it. Research, then drafting, then editing, then reformatting — each done separately, each starting cold. A system changes the math. A research agent feeds a draft agent. A draft agent feeds a repurposing agent. The input is a topic. The output is a week of content. Every run of the system produces the same structure. The quality is more consistent than manual production on a good day.
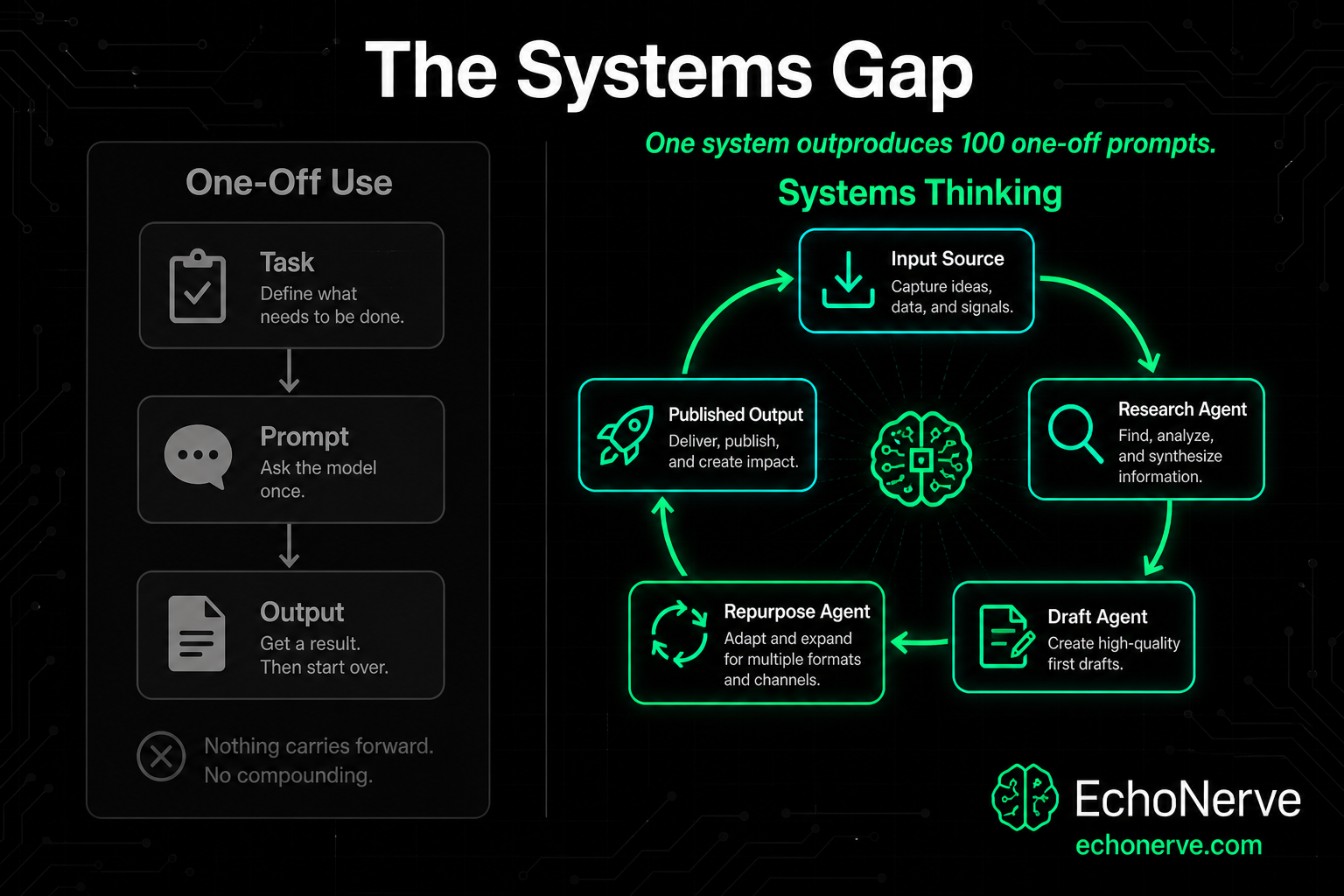
The 88% never get compounding results because they never stop starting from scratch. They get better at prompting. They do not get better at building.
Gap 3: The Signal Gap The 88% consume AI news. The 6% filter it. There is a real difference between knowing a new model launched and knowing whether that model changes anything in your work. New models launch every few weeks. New tools launch every few days. The 88% feel the pressure to evaluate all of it. They switch tools based on launch hype. They subscribe, experiment for three days, and move on. The 6% run a tight stack. They update it when they have real evidence. They know which capabilities are stable, which are overhyped, and which need more time before they are production-ready. This comes from reading model system cards, not press releases. It comes from understanding what benchmarks measure, not what marketing claims. It comes from testing, not reading about testing. The signal gap is the hardest to close. But it is the one that most determines whether you get ahead of the market or stay reactive to it.
Which Group Are You In?
Eight questions. Answer based on how you work right now — not how you intend to work.
1. Do you have a written system prompt or context file that loads before every AI session? Not in your head. Written down. Used every time.
2. Have you built any automated AI workflow that runs without you prompting each step? Not planned. Running.
3. Do you have a prompt library you update and improve? A record — what worked, what did not, and why.
4. Do you know the functional difference between Claude Sonnet, Opus, and Haiku — and when to use each? Not the marketing descriptions. The behavioral differences and cost tradeoffs you have tested.
5. Have you read any frontier model system card in the last 90 days? The actual document — from Anthropic, Google, or OpenAI. Not an article about it.
6. When an AI output is bad, do you diagnose why — or do you try again? Do you know which part of your instruction produced the wrong output?
7. Do you have a process for turning AI outputs into published work within 24 hours? Not a vague intention. A process you run.
8. Do you know what MCP is — and name two ways it changes what AI is able to do? If you need to search for the answer, the answer is no.
Your score:0-2 yes: You are in the 88%. Most people are. The gap is not intelligence — it is system design. That is fixable.3-5 yes: You are in transition. You have the instincts. Build the systems behind them.6-8 yes: You are in the 6%. The gap was never about tools. Most people never take the time to audit where they stand — which is part of why most people stay where they are.
How to Cross the Gap
Three starting points. Each takes two hours or less. Each changes every AI session you run after it.
Build one context file this week. A single document. 300-500 words. It tells the model who you are, what you are working on, and what outputs you need. Your work. Your voice. Your most common tasks. What a good output looks like for you. Load it at the start of every session. The difference shows up in the first response. The research agent I built started with this document. It is not the agent. It is the foundation the agent runs on. Without it, the agent produces generic output. With it, the output is specific, formatted, and usable.
Design one repeatable workflow. Pick a task you do every week. Map it. What is the input? What is the output? What steps happen between? Write it down. Then build one workflow that handles two of those middle steps automatically. You do not need custom agents for this. A well-structured system prompt with a defined input format and a defined output format is a workflow. Start there. Run it for two weeks. See what the system produces versus what you produced manually. Then extend it.
Read one model system card. Claude’s system card is public. Gemini’s is public. GPT-4’s technical report is public. Pick one. Read the section on what the model is designed to do and explicitly not designed to do. One hour of reading gives you context most AI users never access. You will understand why certain prompts fail consistently. You will understand where the model’s limits are and where they are not. You will stop blaming the output and start fixing the instruction.
The Gap Does Not Close on Its Own
88% is not a rounding error. It is the result of most people treating AI adoption as a tool problem. Add the right subscription. Get the right results. It is not a tool problem. It is a thinking problem. The 6% think differently about what AI is for and what they need to build to use it at all. The three gaps — context, systems, signal — do not close by using AI more often. They close by using it differently. I built Deep Stack because the research, system design knowledge, and model-level understanding needed to close those gaps is scattered across system cards, technical papers, and thousands of hours of experimentation. Most people do not have the time to find it and piece it together. Deep Stack is the architecture, not the curriculum. The difference matters: a curriculum tells you what to learn. An architecture defines what to build and in what order — so the system you end up with is structurally sound, not randomly assembled. Access to Deep Stack is readiness-based. The self-audit above is the first gate — not because access is artificially restricted, but because someone who has not yet mapped their current stack will get noise from the system, not signal.
If the audit showed you gaps, that is your entry signal. → See the Deep Stack architecture If you are still orienting, every article on this site is a sequenced layer.
Follow the audit’s direction — the path is deliberate, not random.