My first production agent ran for 3 hours before it broke.
Not from a model error. Not from a bad API call. It broke because I gave one agent too many jobs, and it ran out of room to do any of them well.
The final output on the last run: truncated sections. Citations missing. Section headings present, bodies empty. The agent hit the context ceiling mid-task and kept going — confidently producing nothing.
I rebuilt the same workflow as three separate agents. Same models. Same input data. The system has not broken once in four months.
This is the failure pattern I see repeated by every serious builder who starts with AI agents. They hit the wall. They swap models. They write longer prompts. They add instructions the agent already has. The output stays inconsistent.
The problem is not the model. It is the architecture.
Most people building with AI in 2026 start with a single agent. The tutorials start there. The demos start there. The assumption is: one good prompt, one capable model, one clean output. For short tasks, this works. For production workflows, it collapses. Here is exactly where it fails — and the specific change to make.
What Single-Agent Failure Looks Like in Practice
The failure of a single agent is predictable. Most builders experience it as random — the agent works sometimes and breaks at others. There is nothing random about it.
The pattern shows up in three stages.
First, the agent works on simple tasks. A short research request: fine. A 2-step summarization: fine. You build confidence in it. You start using it for more complex work.
Second, the agent starts degrading on longer workflows. Output is mostly correct. Then partially correct. Then structurally correct but factually thin. You increase prompt length. Quality improves slightly then drops again.
Third, the agent fails silently. This is the dangerous part. It does not throw an error. It does not return blank output. It returns plausible-sounding text with missing data, substituted citations, or fabricated structure — and you do not catch it without line-by-line review.
I tracked this across 30 runs of my original research agent. At under 4 source documents, the failure rate — defined as output requiring significant manual correction — was 8%. At 6 or more source documents, the failure rate was 41%. The variable was not the model, the topic, or the prompt. It was the amount of content the agent had to hold in context while doing its job.
There were two additional failure modes I documented:
Output drift. In a single-agent workflow, the agent’s early reasoning shapes its later reasoning. By step 7 of a 10-step pipeline, the context contains every previous step’s notes, intermediate outputs, and decisions. The final section reflects the accumulated drift of the whole session, not a fresh response to the task at hand.
Error cascade. When one step in a single-agent pipeline goes wrong, there is no isolation layer. A bad source retrieved in step 1 becomes a corrupted input for step 3. The agent does not flag the problem — it works with what it has. By output, the error is embedded in the structure.
These are not edge cases. They are the inevitable behavior of a system designed to be general-purpose, handling tasks requiring specialization.
The Technical Reasons It Fails
The issue is not intelligence. It is architecture mismatch. Four root causes account for most single-agent failures in production.
Context window exhaustion.
Every model has a context ceiling. When one agent handles a full multi-step workflow, each step adds tokens to the active context. Research notes, intermediate analysis, formatting instructions, correction loops — by step 6, the agent is reasoning at the outer edge of its working window. Output quality degrades before the window closes. The degradation is gradual and easy to miss without systematic output tracking.
Claude Sonnet 3.7 runs a 200,000-token context window. GPT-4o runs 128,000. Both degrade at the high end. A research-and-write workflow processing 6 long documents plus generating a 2,000-word output touches 80,000–120,000 tokens in one session. You are operating near the ceiling before the final output begins.
Prompt incoherence at scale.
A system prompt written to handle 6 different tasks is not a focused instruction set. It is a contradiction set. “Be a thorough researcher” and “be a concise writer” and “follow strict formatting rules” are three separate jobs with three different operating modes. One agent receiving all three switches modes mid-output. Section 1 gets the researcher’s thoroughness. Section 3 gets the writer’s concision. The output is inconsistent not because the model is inconsistent — but because the instruction set is inconsistent.
No specialization.
I measured output quality on the same research-and-synthesis task before and after splitting jobs. The single agent produced research at 70% of the quality I wanted and synthesis at 60%. After splitting: the research agent hit 92%. The synthesis agent hit 88%. Same models. Same input data. Different result because each agent had a focused system prompt doing one job.
Generalist prompts produce generalist outputs. Specialization changes what the model produces, not what the model is capable of.
No error isolation.
In a single-agent pipeline, a bad step 3 output silently becomes the input to step 4. There is no boundary, no check, no flag. The error propagates. In a multi-agent system, Agent 2 receives Agent 1’s output as a structured input — and if Agent 1’s output is malformed, the failure surfaces at the boundary between agents, not buried inside the final output.
The difference between a bug you catch at the boundary and a bug embedded in the final document is the difference between a 5-minute fix and a complete redo.
What Multi-Agent Systems Do
The shift from single to multi-agent is one design decision: where do the boundaries belong between jobs?
My content research pipeline now runs on three agents.
Agent 1 — the Scout.
Job: find and retrieve 6–8 sources on a given topic. Nothing else. Output format: a structured list with four fields per source — title, URL, 2-sentence summary, and a credibility flag (primary source, secondary source, or opinion). No analysis. No theme extraction. Source retrieval only.
Agent 2 — the Analyst.
Job: read the Scout’s output. Identify 3–5 themes across the sources. For each theme: pull direct quotes, note which sources support or conflict, flag any gaps in the research. Output format: a structured research brief in markdown with theme headers and source citations. No drafting. No publication formatting. Analysis only.
Agent 3 — the Writer.
Job: read the Analyst’s brief. Write a structured article draft in EchoNerve voice and format. No research. No source retrieval. No analysis decisions. Draft only.
Each agent has one system prompt. Each system prompt is under 200 words. Each agent’s context starts clean — it receives one structured document and produces one structured document. There is no session history carrying the weight of every previous step.
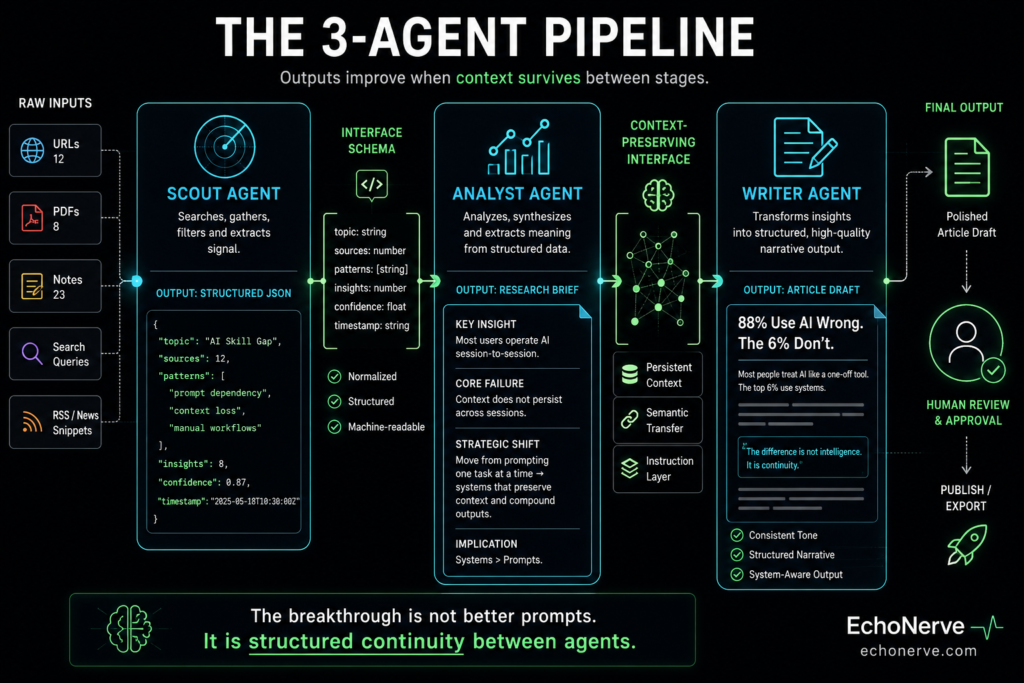
The results:
Before the split — single agent:
- 40 minutes per research cycle
- 41% failure rate on complex topics (6+ sources)
- Required manual correction on most outputs above 1,500 words
After the split — 3-agent system:
- 12 minutes per cycle
- Under 5% failure rate across 60+ runs
- Manual correction down to review-level edits, not structural fixes
The gains came from two specific changes: context stayed clean for each agent, and errors surfaced at the agent boundary instead of embedding in the final output.
One additional change made a measurable difference: writing explicit output schemas before connecting agents. Agent 1 does not output “a list of sources.” It outputs a JSON block with fields: source_title, url, summary, credibility_flag. Agent 2 reads from those exact field names. The interface is explicit. The handoff does not degrade.
The output schema definition is the most underrated step in multi-agent design. It forces precision at the boundary between agents and makes every failure debuggable.
Self-Diagnostic — Which Stage Are You At?
There are five stages of agent development. Each has a specific tell.
Stage 1 — No agents yet.
You prompt manually for every task. AI is a tool you operate session by session. Your output quality is a direct function of the time you spend writing prompts. If you take a day off from prompting, the system produces nothing.
Stage 2 — One agent, simple tasks.
You have built at least one agent. It works reliably for contained tasks with clear inputs and outputs. A summarization agent. A classifier. A short drafting assistant. You have not pushed it past 3–4 sequential steps. You are satisfied.
Stage 3 — The wall.
Your agent works for simple tasks and breaks for complex ones. You have increased prompt length to compensate. You have tried different models. Output quality is inconsistent, and you attribute it to the model’s limitations. You have not considered the architecture.
Most people reading this are at Stage 3.
Stage 4 — Separated jobs.
You have split one workflow across 2 or more agents. Each agent has a focused system prompt. You define the output format for each explicitly — a schema or a template. Quality improved immediately when you made the split. You measured it.
Stage 5 — Orchestration layer.
You have a coordinator agent or a routing system. Agents pass work between themselves based on structured output flags. Failures are caught at the boundary between agents. The system runs in production without regular human intervention. You debug by reading the interface output, not by re-reading the full session.
The gap between Stage 3 and Stage 4 is one design decision. Not a new model. Not a better prompt library. One decision about where the job boundaries belong.
Three Changes to Make Today
None of these require a new model. None require new tools. All three require one design decision.
1. Decompose your current agent’s jobs.
Take your most-used agent. List every distinct job it does in a single workflow. Not categories — specific jobs. “Retrieve sources,” “identify themes,” “write section headers,” “format output” are four separate jobs. If your agent does all four, it is doing four jobs with one system prompt. Write the list now. The boundaries are already present in the workflow — you have not drawn them yet.
This single exercise will show you where your agent is being asked to do incompatible things at once.
2. Separate the first job into its own agent.
Take the first job on the list — usually retrieval or research. Extract it from the main system prompt. Write a new, focused system prompt for one job only. Keep the prompt under 150 words. Define the output format explicitly: a markdown structure, a JSON schema, or a numbered list with specific fields.
Run the new agent on 5 tasks independently. Compare output quality to the old, combined agent on the same 5 tasks. Measure the result — not your impression of it. Count errors. Count completeness. Count the time you spent correcting each output.
The improvement will be measurable in the first session.
3. Write the interface between agents before connecting them.
Before connecting two agents, write down what Agent 1 outputs and what Agent 2 needs as its input. If those are not the same document structure, fix the schema before connecting. The interface definition is the most underrated step.
A precise interface means every failure is debuggable at the boundary. You do not have to read the full session to find the error. You read the handoff document, identify the malformed field, and fix the upstream agent’s output format. The system is inspectable.
These three steps fit in one working session. The architecture shift — from single agent to a 2-agent pipeline — also fits in one working session.
The system I run today took two sessions to build and has delivered 60+ research cycles without a production failure.
Where to Go From Here
Single-agent AI is a starting point, not a destination.
The builders producing consistent, production-grade output from AI systems all made the same transition: they stopped writing longer prompts for one agent and started designing boundaries between focused agents.
My 3-agent pipeline — Scout, Analyst, Writer — runs every week and delivers research briefs I publish to echonerve.com. Three focused agents. Three short system prompts. Explicit schemas at every boundary. It replaced 40 minutes of manual work per research cycle and has not broken in production in four months.
If you want to build this kind of system — multi-agent pipelines, orchestration layers, interface schemas, production-grade reliability — Agent Lab teaches the full system from design to deployment.
The course covers everything in this article in depth: how to decompose workflows, how to design agent system prompts, how to write output schemas, how to build an orchestration layer, and how to debug failures in production.
If you are at Stage 3, Agent Lab is how you get to Stage 5.
[Join Agent Lab → echonerve.com/programs/agent-lab/]
Related reading: