Every week, my content pipeline produces:
— 1 long-form article (2,500 words)
— 4 social posts across LinkedIn, X, and Substack Notes
— 2 email brief drafts
— 1 research digest
I spend about 3 hours on all of it.
Three Claude agents handle the rest.
The shift didn’t happen gradually. It clicked into place in a single session, four months ago. I sat down and mapped the entire pipeline at once — research in, structured digest out, the digest fed into a draft, the draft split into four platform-ready posts.
Before building the system, content was taking me 8 to 10 hours a week. Research. Drafting. Reformatting for LinkedIn. Writing the email version. The Substack note. All of it scattered across different sessions, different tools, different mental states.
After: 2 to 3 hours a week. Same output volume. Better consistency. Because the structure stays fixed, the quality is more repeatable than anything I produced when doing it manually.
This article explains the full system. What each agent does. What each agent needs to work. And where to start building yours.
Why One-at-a-Time Prompting Fails at Scale
Most people using AI for content hit a ceiling fast.
Single-task prompts work fine. Write me an email. Summarize this article. Give me a LinkedIn post. Each output is usable. The problem shows up when you try to scale it.
Every session starts from zero. The model has no memory of your style, your previous work, or what you’re building toward. You provide context every time.
Tasks stay siloed. Research happens in one conversation. Drafting in another. Social posts in a third. The model has no awareness of what happened in the other sessions.
The human becomes the connector.
You copy the research output into the drafting prompt. You copy the draft into the repurposing prompt. You’re moving outputs from one AI session to the next by hand.
At this point, you haven’t automated anything. You’ve outsourced the typing. The coordination overhead still falls on you.
I ran this pattern for about six months before changing my approach. I had Claude. I had a working writing process. I was still spending 8 to 10 hours a week on content because I was prompting one task at a time with no structure connecting the steps.
The fix isn’t better prompts. It’s a different architecture.
When you design a pipeline instead of prompting one task at a time:
- Each agent holds a defined role with a persistent context
- Output from Agent 1 flows directly into Agent 2
- The human role shifts from doing to reviewing

The architecture creates the leverage. Not the prompt.
The 3-Agent System — Architecture
The system has three agents. Each has a single job.
No agent tries to do everything. No agent improvises. Each runs a defined process on a defined input and produces a defined output.
Here’s how each one works.
Agent 1: The Research Collector
Input: A topic or list of URLs.
The agent pulls content from each source — saved links, articles, infographics, RSS items — and produces a structured research digest. Key insights. Data points with sources. Contradictions between sources. Gaps in the coverage. Two or three article angles based on what it found.
The system prompt is built around signal extraction. Not summarizing. Not paraphrasing. Identifying what matters and flagging what doesn’t.
Output: A single .md research note, structured for direct handoff to Agent 2.
Agent 2: The Draft Writer
Input: The research note from Agent 1.
The agent writes the full article draft. It uses a fixed article template: hook, section breakdown, CTA. It writes in EchoNerve voice — first-person, spartan, no banned words. It follows the writing rules loaded into its context file.
The system prompt is built around style consistency and structure adherence. The agent doesn’t invent the angle. I choose the angle. The agent executes it.
Output: A 2,000 to 2,500 word draft in the article template format. First pass is 70 to 80 percent ready. My edit pass takes 20 to 30 minutes.
Agent 3: The Repurposer
Input: The finished article after my edit.
The agent produces four pieces: a LinkedIn post, a Substack Note, an X thread, and an email brief. Each formatted to the platform spec — line breaks, length, hook style.
The system prompt enforces platform rules. No duplicating the hook across platforms. No generic summaries. Each piece is its own entry point to the same core idea.
Output: Four ready-to-post pieces from a single article.
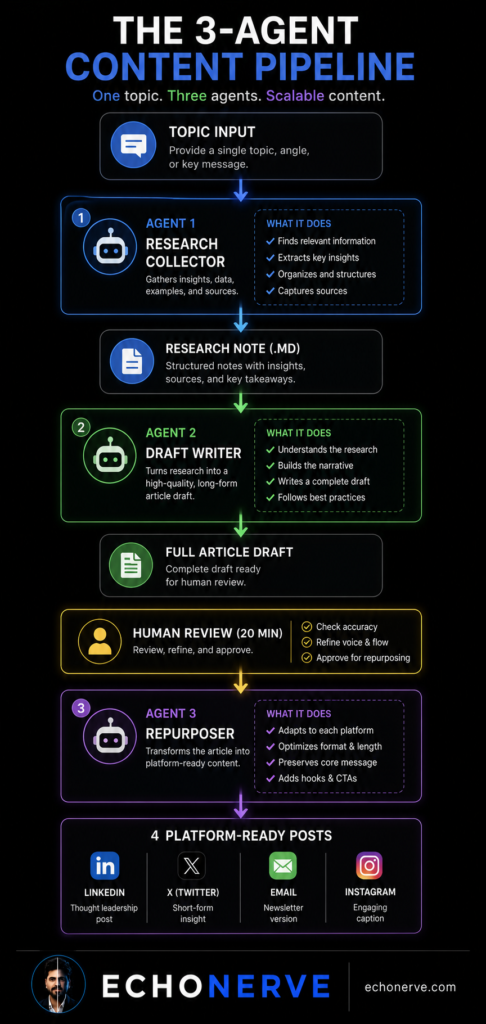
The pipeline flow:
Topic / Source List
↓
[Agent 1: Research Collector]
↓
Research Note (.md)
↓
[Agent 2: Draft Writer]
↓
Full Article Draft
↓
Human Review (20 mins)
↓
[Agent 3: Repurposer]
↓
4 Platform-Ready Posts
Two things worth noting.
First: I appear in the pipeline once. Between Agent 2 and Agent 3. My 20-minute edit pass is the only point where I touch production work. Everything else runs without me.
Second: the system starts with a two-sentence input. I write the topic and two or three source URLs. The rest is the pipeline.
What Each Agent Needs to Work
Most people try to build AI workflows and stop before shipping anything.
The failure point is almost always the same. They give the agent a vague instruction and expect consistent output. The output is inconsistent. They stop.
The solution isn’t a better prompt. It’s giving each agent the three inputs it needs before it will run reliably.
1. A system prompt with role, constraints, output format, and banned behaviors
“You are a research assistant” produces generic output.
The system prompt format I use:
Role: What this agent is and what it does.
Constraints: What it does not do. Where it stops.
Output format: The exact structure, headers, and sections.
Banned behaviors: What failure looks like, so the agent avoids it.
Here is the abbreviated structure for Agent 1 (the full version lives in Agent Lab):
You are a research analyst for EchoNerve, an AI systems publication.
Your job: Given a topic or list of URLs, produce a structured research digest.
Output format:
- Key insights (5-8 points, specific, quotable)
- Data points with sources
- Gaps: what the sources do not cover
- Article angles: 2-3 ideas based on what you found
Rules:
- Extract signal. Ignore noise.
- Flag if two sources contradict each other.
- Do not summarise. Identify what matters.
The difference between a system prompt and a chat message is precision. Chat messages get interpreted. System prompts get followed.
2. A context file loaded before every session
Each agent needs a reference file. Who is EchoNerve. What is the writing style. What are the banned words. What does the article template look like. What does the output from the previous agent look like.
This is the CLAUDE.md equivalent for the content pipeline. It’s the component most builders skip. Without it, the agent reconstructs context from scratch every session.
3. A consistent input and output format
Agent 1’s output feeds Agent 2. Agent 2’s output feeds Agent 3. If any output is unstructured, the next agent has to interpret it rather than process it. Interpretation introduces variance.
I use fixed headers in every output. The research note has four sections. The draft follows the article template. The repurposed posts are separated by platform heading.
When all three inputs are in place, the pipeline runs. When one is missing, the pipeline degrades.
Real Weekly Numbers
Four months into running this system, here’s what the numbers look like.
Content production time before the system: 8 to 10 hours a week.
Content production time after: 2 to 3 hours a week.
All of those hours are review and editorial decision work. Zero production work.
First-pass draft quality from Agent 2: 70 to 80 percent ready to publish. My edit pass runs 20 to 30 minutes per piece. I fix the hook angle when it’s off. I add the personal beat. I sharpen the CTA. The structure, the voice, the style rule compliance — all handled by the agent.
Weekly output with the system:
— 1 long-form article (2,000 to 2,500 words)
— 4 social posts across LinkedIn, X, and Substack Notes
— 2 email brief drafts
All from one research pass.
Time per deliverable before the system: roughly 2 hours per piece, including context-switching and reformatting.
After: about 40 minutes per piece — and 30 of those minutes are me reviewing what the agents produced.
A 2026 freelancer productivity study found deliverables taking 6 hours now take 2.5 hours with AI workflows. My numbers go further because the pipeline eliminates reformatting entirely. The agents handle the platform conversion.
What still requires me: the hook angle, the core argument, which personal story beats to include, the CTA logic, the edit pass.
What doesn’t require me: research aggregation, first-pass drafting, platform reformatting, structural consistency, style rule compliance.
The creative decisions are still mine. The production work isn’t.
What to Build First If You’re Starting From Zero
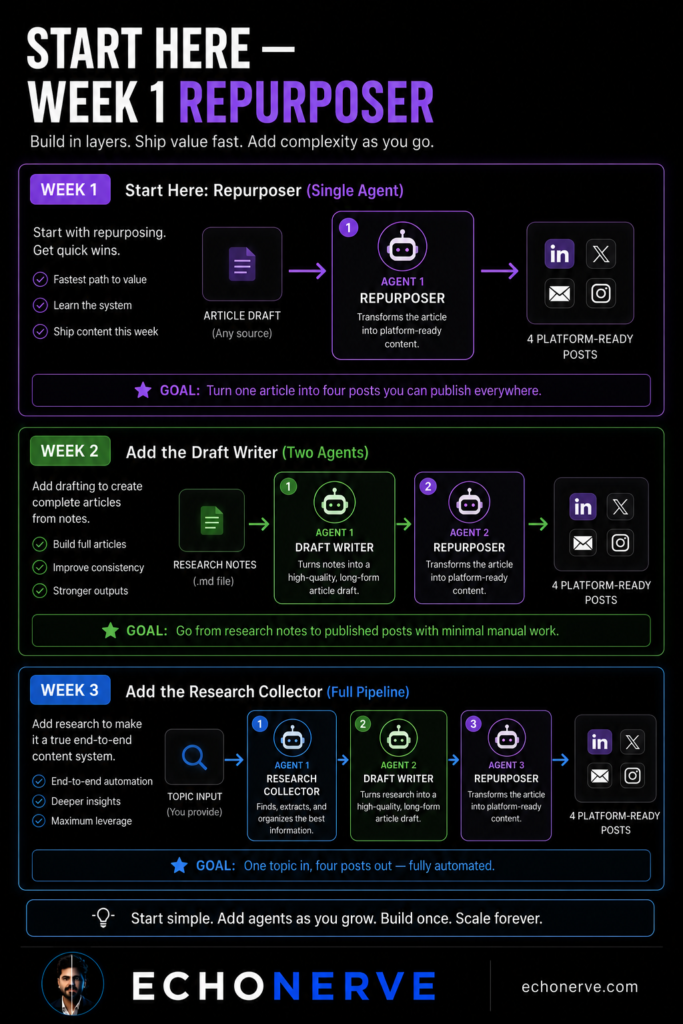
Don’t start with three agents.
Building all three at once is the fastest path to a system that doesn’t work. Each agent needs its own system prompt, context file, and output format. Getting all three right simultaneously means debugging three things at once.
Start with one.
Week 1: Build the Repurposer.
Take your best existing article. Feed it to a single agent with a platform-specific system prompt. Get four posts back.
This is the highest-value immediate build. You already have the article. You already know what it’s about. The only variable is whether the agent’s output meets your publishing standard with light edits.
Start here. Get a working Repurposer before adding anything else.
Building the Repurposer teaches you the two most important skills: writing a system prompt with precision constraints, and auditing agent output against your actual publishing standards.
Week 2: Add the Draft Writer.
Use your existing research notes as input. Let the agent produce a first draft against your article template. Your job in Week 2: edit the draft into something you’d publish.
You’re learning what the agent gets right without added guidance — structure, length, basic style adherence — and where the system prompt needs tighter constraints.
Week 3: Add the Research Collector.
Now the pipeline is complete. Input is a topic or source list. Output is published content across four platforms.
Three weeks. One agent at a time. The pipeline works when each agent works individually. Don’t skip the sequencing.
The Working Version Is Already Built
The system took me two weekends to design.
The JSON configs took longer to debug than I expected. Each agent’s system prompt went through six iterations before the output was consistent enough to trust.
Most “here’s my AI workflow” content shows the finished state. It skips the two weeks where nothing worked while I figured out what the system prompts were missing.
I built Agent Lab to give you the working version of what took me weeks to sort out.
The exact system prompts for all three agents. The JSON configuration files. The context file templates — the about-me.md, the voice rules file, the full style guide. The repurposing format library for LinkedIn, Substack Notes, X threads, and email briefs. All tested and ready to deploy.
You still own the ideas. You still make the editorial decisions. You still write the 20 percent — your angle, your voice, your examples.
The system handles the other 80 percent.
Join Agent Lab → echonerve.com/programs/agent-lab/